
Notice
Recent Posts
Recent Comments
Link
yurim45 님의 블로그
6. SQL의 기본(2) 본문
1. SELECT 구문과 활용
(1) DML (Data Manipulation Language)
- DML의 개념과 특징
- 데이터베이스의 데이터를 조작, 검색/추가/삭제/갱신 등 수행하는 SQL 언어
| SQL 명령어 | 설명 |
| INSERT | 새로운 레코드를 삽입하는 명령어 |
| SELECT | 조건에 맞는 레코드를 선택하여 반환하는 명령어 |
| UPDATE | 선택된 레코드의 속성값을 수정하는 명령어 |
| DELETE | 선택된 레코드를 삭제하는 명령어 |
- INSERT 구문- 데이터 입력
- 명령어 형식
- INSERT INTO 테이블명 (column명, ...) VALUES (value 값, ...)
- INSERT INTO 테이블병 VALUES (값, ...)
- 명령어 형식
INSERT INTO
employees (employee_id, first_name, last_name, email, hire_date, job_id)
VALUES (405, 'Ruby', 'Kim', 'ruby@mail.com’, TO_DATE('2025-04-12', 'YYYY-MM-DD'), 'IT_PROG');
- UPDATE 구문- 데이터 수정
- 명령어 형식
- UPDATE 테이블명 SET column명=value
- WHERE 절을 이용하여 조건 지정. WHERE 절이 없을 경우 모든 행이 업데이트 됨!!
- 명령어 형식
UPDATE employees SET job_id = 'AC_ACCOUNT' WHERE employee_id = 405;
- DELETE 구문- 데이터 삭제
- 명령어 형식
- DELETE FROM 테이블명
- WHERE 절을 이용하여 조건 지정
- 명령어 형식
DELETE FROM employees WHERE employee_id = 405;
(2) SELECT 구문의 형식과 활용
- SELECT 구문- 데이터 선택/가져오기
- 명령어 형식
- SELECT 컬럼명 FROM 테이블명
- SELECT * FROM 테이블명
- SELECT DISTINCT 컬럼명 FROM 테이블명
- DISTINCT: 중복 제거
- ALIAS(별칭)을 설정하여 간결하고 명확한 SQL 작성 가능, 별칭을 사용한 경우 별칭을 이용한 참조 필수
- DUAL: 오라클이 제공하는 기본 더미 테이블, 연산 수행을 위해 사용
- 명령어 형식
SELECT S.NAME, B.NAME FROM student_t AS S, band_t AS B WHERE S.bcode = B.bcode;
- SELECT 구문- 산술연산자의 활용
- 산술 연산자: 수학의 사칙연산, NUMBER / DATE 등의 데이터에 사용
- 사칙연산: +, /, +, -
- 나머지 연산: % (Oracle는 MOD 함수를 이용)
- 괄호 (): 먼저 처리해야 할 것을 지정
- 산술 연산자: 수학의 사칙연산, NUMBER / DATE 등의 데이터에 사용
SELECT 1+1, 10/2 FROM DUAL;
SELECT C1+C2 AS A, C1-C2 AS B FROM sample_t;
- SELECT 구문- 문자 연결 연산자와 문자함수의 활용
- 문자 연결 연산자: 여러 개의 문자열을 하나의 문자열로 합성
- 오라클: ||
- SQL 서버: +
- MariaDB: CONCAT()
- 문자 연결 연산자: 여러 개의 문자열을 하나의 문자열로 합성
SELECT ‘H’ || ‘I’ AS HI FROM DUAL;
SELECT NAME || ‘선수, HEIGHT || ‘cm’ FROM member_t;
- SELECT 구문- 문자 연결 연산자와 문자함수의 활용
- 문자함수: 문자열을 특정 목적에 따라 처리하는 함수
- CHR (숫자): 아스키 코드에 대한 문자 출력
- LOWER (문자열): 소문자열로 변환
- UPPER (문자열): 대문자열로 변환
- LTRIM (문자열, 점검문자): 문자열의 왼쪽부터 점검문자를 제거, 점검문자를 지정하지 않으면 공백 문자를 대상으로 함
- RTRIM (문자열, 점검문자): 문자열의 오른쪽부터 점검문자를 제거, 점검문자를 지정하지 않으면 공백 문자를 대상으로 함
- TRIM (문자열, 점검문자): 문자열의 양쪽부터 점검문자를 제거, 점검문자를 지정하지 않으면 공백 문자를 대상으로 함
- SUBSTR (문자열, 시작점, 길이): 문자열의 시작위치 부터 길수(개수)만큼 추출, 길이를 지정하지 않은 경우 끝까지 추출
- LENGTH (문자열): 문자열의 길이 반환
- REPLACE (문자열, 대상 문자열, 대체 문자열): 문자열에 포함된 대상 문자열을 대체, 대체 문자열을 지정하지 않으면 제거
- LPAD (문자열, 길이, 문자): 설정한 길이의 문자열이 될 때까지 문자열의 왼쪽을 지정한 문자로 채움
- 문자함수: 문자열을 특정 목적에 따라 처리하는 함수
# TRIM
SELECT LTRIM(‘ CHRIS’) FROM DUAL;
SELECT TRIM(‘~~~Hi~~~’, ‘~’’) FROM DUAL;
# LPAD
SELECT SUBSTR(‘MyHome’, 3) FROM DUAL;
SELECT SUBSTR(‘YourHome’, 1, 3) FROM DUAL;
SELECT REPLACE(‘MyHome’, ‘My’, ‘Your’) FROM DUAL;
SELECT LPAD(‘Hi’, 5, ‘~’) FROM DUAL;
- SELECT 구문- 숫자함수의 활용
- 숫자 함수: 숫자 데이터를 특정 목적에 따라 처리하는 함수
- ABS (숫자): 절대값을 반환
- SIGN (숫자): 수의 부호를 반환 (양수 : 1, 음수 : -1, 0 : 0)
- ROUND (숫자, 자리수): 지정된 소수점 자리수로 반올림, 자리수를 지정하지 않을 경우 0을 기본값으로 사용
- TRUNC (숫자, 자리수): 지정된 소수점 자리수까지 버림하여 반환, 자리수를 지정하지 않을 경우 0을 기본값으로 사용
- CEIL (숫자): 소수점 이하의 수를 올림 한 정수를 반환
- FLOOR(숫자): 소수점 이하의 수를 버림 한 정수를 반환
- MOD(숫자1, 숫자2): 나머지를 반환, 숫자2가 0일 경우 숫자1을 반환
- 숫자 함수: 숫자 데이터를 특정 목적에 따라 처리하는 함수
SELECT ROUND(123.76, 1) FROM DUAL;
SELECT ROUND(173.76, -2) FROM DUAL;
SELECT TRUNC(123.76, 1) FROM DUAL;
SELECT TRUNC(123.76, -1) FROM DUAL;
SELECT CEIL(12.77) FROM DUAL;
SELECT FLOOR(25.4) FROM DUAL;
SELECT FLOOR(-25.4) FROM DUAL;
SELECT MOD(15, -2) FROM DUAL;
SELECT MOD(-15, -2) FROM DUAL;
- SELECT 구문- 날짜함수의 활용
- 날짜함수: 날짜 데이터를 특정 목적에 따라 처리하는 함수
- SYSDATE: 현재의 연, 월, 시, 분, 초를 반환
- EXTRACT(단위 FROM 날짜): 날짜 중 특정 단위의 데이터를 추출하여 반환 (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND)
- ADD_MONTHS(날짜, 개월 수): 날짜에 지정한 개월 수를 더한 날짜를 반환 (기준 날짜가 없을 시 마지막 일자 반환)
- 날짜함수: 날짜 데이터를 특정 목적에 따라 처리하는 함수
SELECT SYSDATE FROM DUAL;
EXTRACT (YEAR FROM SYSDATE) AS YEAR FROM DUAL;
ADD_MONTHS(TO_DATE(‘2025-04-12’, ‘YYYY-MM-DD’), 1) AS NEXT FROM DUAL;
- SELECT 구문- 데이터 형식 변환 함수의 활용
- 데이터 변환 방식의 종류
- 명시적 변환: 데이터 형식 변환 함수를 이용하여 명시적으로 변환
- 암시적 변환: 연산 방식에 따라 자동으로 변환
- 데이터 형식 변환 함수
- TO_NUMBER(문자열): 숫자형으로 변환
- TO_CHAR(데이터, 포맷): 숫자, 날짜 데이터를 지정한 포맷의 문자열로 변환, 포맷 생략 시 전체를 문자열로 변환
- TO_DATE(문자열, 포맷): 포맷에 따라 날짜형으로 변환 (YYYY, MM, DD, HH, HH24, MI, SS)
- 데이터 변환 방식의 종류
SELECT TO_CHAR(123) FROM DUAL;
SELECT TO_CHAR(SYSDATE, ‘YYYYMMDD HH24MISS‘) FROM DUAL;
- SELECT 구문- NULL 관련 함수의 활용
- NULL 관련 함수
- 결과가 NULL일 경우 어떤 방식으로 처리할 지 지정하는 함수
- NVL(인자1, 인자2): 인자 1이 NULL일 경우 인자2를 반환, NULL이 아닌 경우 인자 1을 반환
- NULLIF(인자1, 인자2): 인자1과 인자2가 같으면 NULL을 반환, 같지 않은 경우 인자1을 반환
- COALESCE(인자1, 인자2, 인자3, ...): 전달한 인자 중 NULL이 아닌 최초의 인자의 값을 반환
- NVL2(인자1, 인자2, 인자3): 인자1이 NULL이 아닌 경우 인자2를 반환, NULL일 경우 인자3을 반환
- 결과가 NULL일 경우 어떤 방식으로 처리할 지 지정하는 함수
- NULL 관련 함수
SELECT USER_NO, NVL(GRADE, 0) AS HAKJUM FROM user_t;
SELECT USER_NAME, COALESCE (TEL, MAIL, SOCIAL) AS USER_CONTACT FROM user_t;
SELECT USER_NAME, NVL2(GRADE, '학점취득', '학점미취득') AS GRADE_CHECK FROM user_t;
- SELECT 구문- CASE, DECODE 구문의 활용
- IF~THEN~ELSE의 논리구조와 유사한 방식
- CASE 구문의 예와 DECODE (오라클 전용)
# ELSE 생략 시 NULL 출력
CASE WHEN GRADE ='A' THEN ‘HIGH’ WHEN GRADE ='B' THEN 'MIDDLE' ELSE 'LOW' END
CASE GRADE WHEN GRADE ='A' THEN ‘HIGH’ WHEN GRADE ='B' THEN 'MIDDLE' ELSE 'LOW' END
DECODE (GRADE, 'A', 'HIGH', 'B', 'MIDDLE', 'LOW')
2. WHERE절의 특징과 활용
(1) WHERE절의 특징과 연산자
- WHERE절의 목적과 기본 형식
- SELECT, UPDATE, DELETE 문에서 조건을 설정하는 구문
- 원하는 조건을 WHERE 이후에 지정
- SELECT * FROM user_t WHERE NAME = ‘Ruby’;
- SELECT * FROM user_t WHERE NAME <> ‘Ruby’;
- UPDATE user_t SET AGE = 30 WHERE NAME = ‘Ruby’;
- DELETE user_t WHERE NAME = ‘Ruby’;
- WHERE절에서 사용할 수 있는 연산자
- 비교 연산자 : = , < , <= , >, >=
- 부정의미의 비교 연산자 : !=, ^=, <>, not 컬럼명 = 값, not 컬럼병명 > 값
- SQL 고유 연산자
- BETWEEN A AND B : A와 B를 포함한 사이의 값
- IN (리스트) : 리스트 내의 값
- NOT BTWEEN A AND B
- NOT IN (리스트)
- IS NOT NULL
- LIKE ‘비교 문자열‘ : 비교 문자열을 포함 (% : 문자열, _ : 하나의 문자)
- IS NULL : NULL 값 확인(※ NULL은 일반 비교연산자로 확인할 수 없음)
- 논리 연산자 : NOT, AND, OR
SELECT NAME, GRADE FROM user_t WHERE NAME LIKE 'Ruby%Kim%';
SELECT NAME, JUMSU FROM user_t WHERE JUMSU in (100, 80, 70);
- 연산자 우선 순위
- 괄호 > 부정 연산자 > 비교 연산자 > 논리연산자
- 괄호
- NOT
- AND
- 비교 연산자, SQL 연산자
- OR
- 문자열 비교: 첫 서로 다른 문자의 값 비교
- CHAR와 VACHAR의 비교: 길이가 다르면 길이가 긴 값이 크다고 판단
- 괄호 > 부정 연산자 > 비교 연산자 > 논리연산자
3. GROUP BY, HAVING, ORDER BY 절의 특징과 활용
(1) GROUP BY 절의 특징과 집계 함수
- 데이터를 그룹 별로 묶어서 처리하기 위해 사용
- 형식 : GROUP BY 기준 컬럼명(기준 컬럼은 2개 이상이 될 수 있음)
- 집계 함수를 이용한 집계 데이터 도출 가능
- GROUP BY 사용 시 SELECT 절에는 GROUP BY에 사용된 컬럼과 집계 함수만 사용할 수 있음
- 집계함수의 특징
- 집계함수란?
- 여러 행들의 그룹을 대상으로 하나의 결과를 반환하는 다중행 함수
- 집계함수의 종류
- COUNT(*): NULL 값을 포함한 행의 개수
- COUNT(컬럼): 값이 NULL인 행을 제외한 개수
- COUNT(DISTINCT 컬럼): 값이 NULL이 아닌 행을 대상으로 중복을 제거한 개수
- SUM(컬럼): 컬럼 값들의 합계
- AVG(컬럼): 컬럼 값들의 평균
- MIN(컬럼): 컬럼 값 중 최소값
- MAX(컬럼): 컬럼 값 중 최대값
- 집계함수란?
SELECT AVG(AGE) AS AVG_AGE FROM user_t;
(2) HAVING, ORDER BY절의 특징과 활용
- HAVING 절의 특징과 활용
- 그룹을 나타내는 결과 집합의 행을 대상으로 조건 지정
- 일반적으로 GROUP BY 절 뒤에 위치하며, GROUP BY 절에서 사용된 컬럼을 조건으로 사용할 수 있음
- SELECT 한 결과를 특정 컬럼을 기준으로 정렬하기 위해 사용하는 구문 (※ 기본 : 임의의 순으로 출력)
- ORDER BY 절에 컬럼을 지정하는 방식
- 컬럼명, ALIAS(별칭), 컬럼 순서를 나타내는 정수
- GROUP BY 절이 있을 경우 GROUP BY 대상 컬럼명만 지정 가능
- 2 개 이상의 컬럼도 지정 가능
- ORDER BY 절의 정렬 옵션: ASC (오름차순, 기본), DESC (내림차순)
- 오라클은 NULL을 최대값으로 판단함
- NULL FIRST, NULL LAST 옵션으로 변경 가능
SELECT JOB, COUNT(*) AS CNT, SUM(SAL) AS TOTAL_SAL FROM emp_t
WHERE DEPT_NO IN ('1', '2', '3')
GROUP BY JOB HAVING COUNT(*) > 2 AND SUM(SAL) > 5000
SELECT NAME, POSITION FROM player_t
WHERE NUMBER IS NOT NULL ORDER BY NAME DESC;
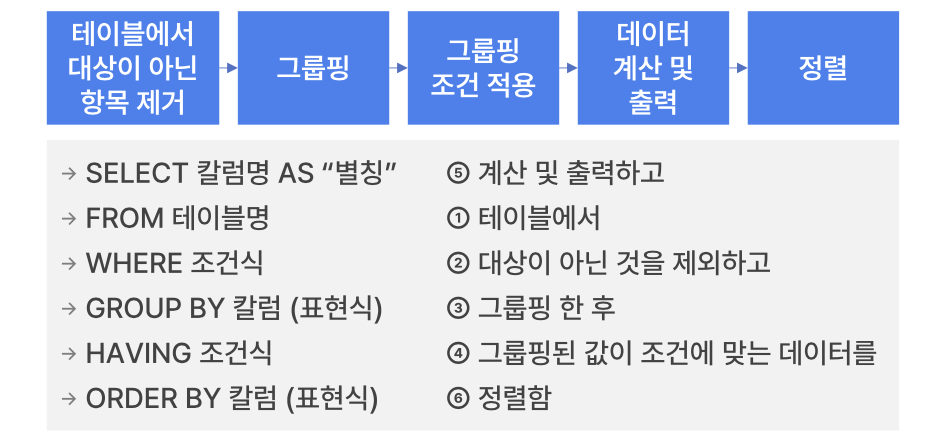
(3) SELECT 관련 구문의 실행 순서
- ORDER BY 절의 특징과 활용
'개발' 카테고리의 다른 글
| 5. SQL의 기본 (1) (0) | 2025.04.05 |
|---|---|
| 4. 논리적 모델링과 정규화 (0) | 2025.03.29 |
| 3. 데이터 모델링의 이해 (0) | 2025.03.23 |
| 02. DBMS의 설치와 활용 - MySQL, Docker (0) | 2025.03.15 |
| 01. 데이터베이스와 SQL 개요 (1) | 2025.03.08 |
'개발' Related Articles
more



